Structured Output Streaming for LLMs
Aug 25, 2025
I had a LLM based feature that was brutally slow. It was taking like 30 seconds to 1 minute to get the response. Obviously, I had to build another library to parse the incomplete structures from the LLM.
Let’s jump into what structured generation is, why it was so slow, and how we can stream it. To understand structured generation we need to understand grammar constrained decoding.
Grammar Constrained Decoding
Grammars in this context are a set of rules that can describe every valid order of tokens. For example subject verb agreement in English, or in JSON, a bracket must terminate the sets of key value pairs. It is commonly expressed through a meta syntax like EBNF.
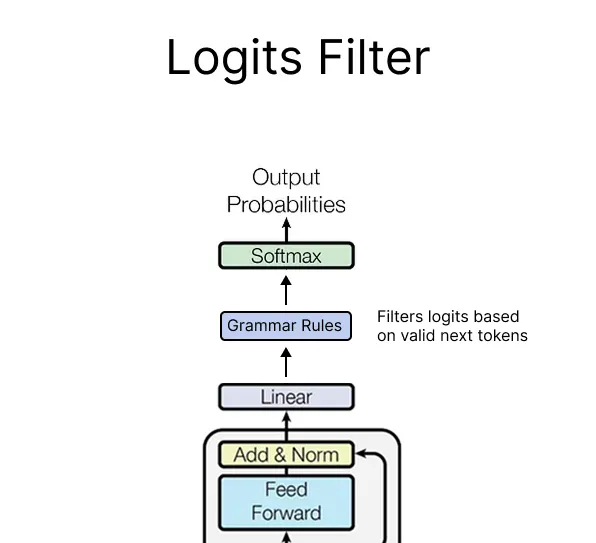
Grammar constrained decoding allows us to filter out all of the LLM responses (tokens) that do not fit in our grammar. This takes the form of masking off the logits of any invalid generated tokens, so we have a guarantee that the output from the LLM will be 100% compliant with our defined grammar.
To achieve the constrained decoding a layer gets added to the transformer before the final softmax layer that will apply the grammar filter to predicted tokens. Since we modify the transformer architecture, this means that to apply grammar rules either the llm provider needs to implement a constrained decoding layer, like openai does, or we have to use an open source model with something like hugging face.
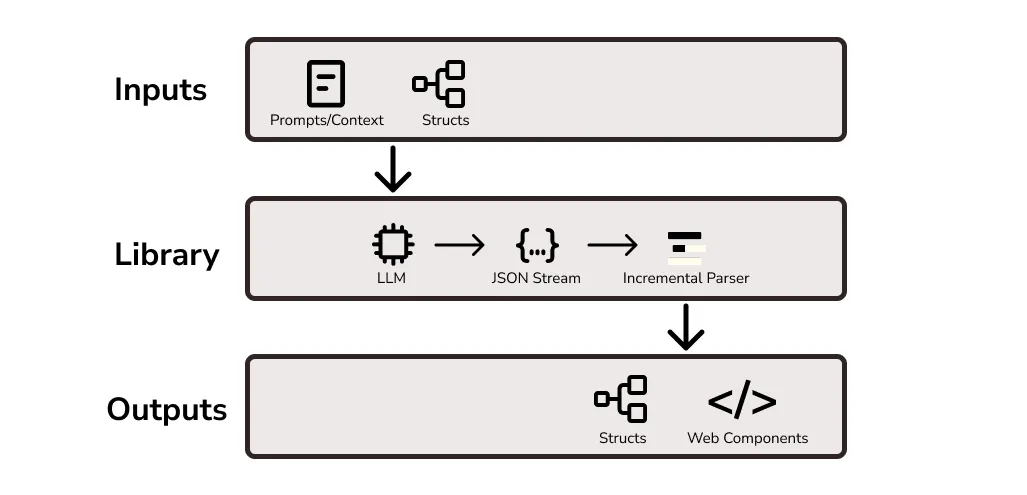
Open Source Structured Streaming Library
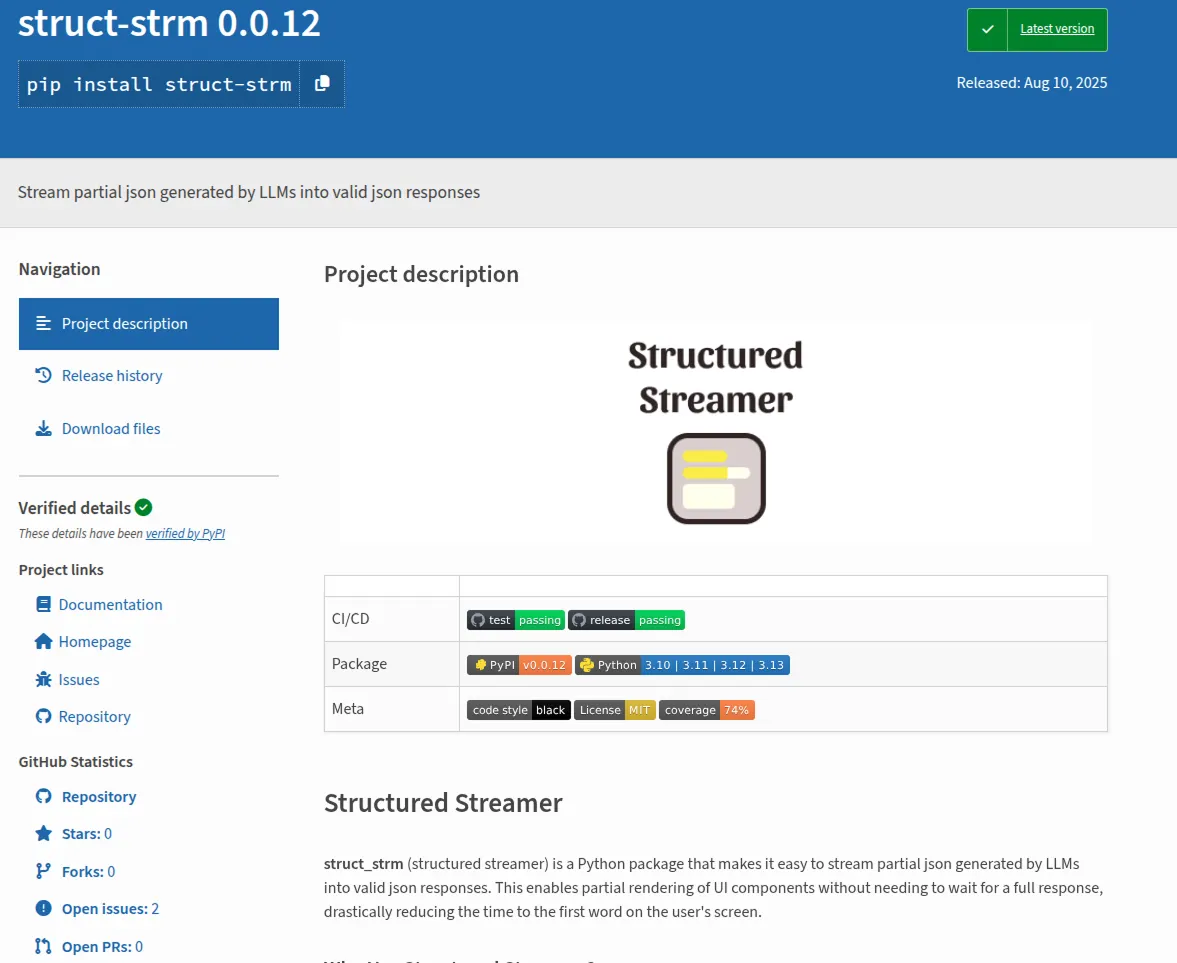
We can get arbitrary structured outputs through grammars now. However, if we can only parse the results once we have the full response, we would end up waiting a really long time in some cases. Let’s take a look at how we can stream this instead. Transformers output tokens one by one, which is conducive to streaming. However, unlike typical chat responses — if we stream a structured output with something like a JSON structure, we won’t have a valid structure until the last closing bracket is returned. My “structured streaming” Python library addresses this issue.
If we are able to stream these structures and parse them without waiting for the full response, we can do a lot of cool things. For example we can:
- Render partial interactive elements immediately, so my ui element can go from taking 30 seconds to first paint to around one second. Since it is so much faster I can also skip using my process queue and just directly stream the content async. So rich tables, hyper-dynamic forms, and other complex components can be good candidates for streaming
- I haven’t played with this yet, but you could trigger jobs mid stream if you’re returning a workflow — so you could have something like cascading workflows with mixed latencies. For example you could kick off a query as soon as the sql is generated while still streaming part of the query explanation back to the user.
- Another use case that streaming could allow for is some sort of early stopping if a validation check fails, so you wouldn’t need to wait until the whole response has been returned to cancel and move to the next step
Let’s look at a quick example of rendering UI elements progressively using this streaming approach.

In this example I’m using FastAPI and HTMX with server sent events to render the html progressively. Since we’re using JSON, you could use your framework of choice like react and just send json instead.
The three main steps in rending these components are, rending the placeholder, rendering the in progress stream, and optionally rendering any additional animations or adding any logic once the full component has been returned.
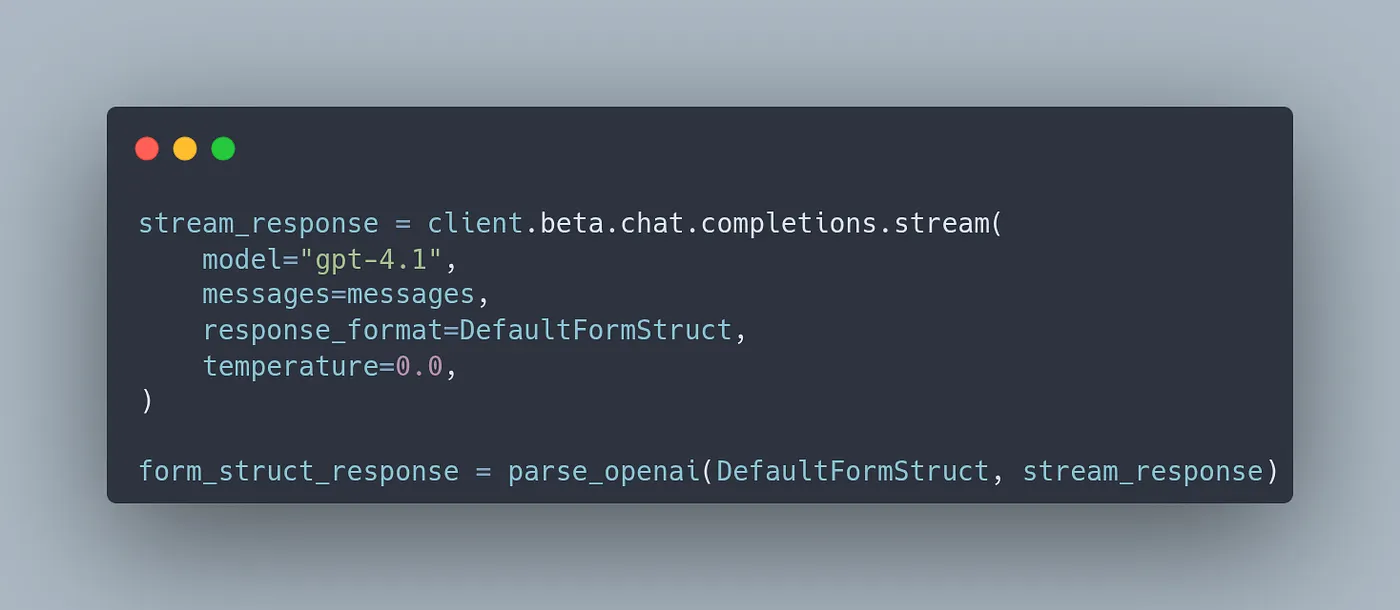
Implementation with the library is as simple as wrapping the stream from your LLM with the parsers from the struct-strm library. Right now, OpenAI is supported and any open source models through Hugging Face are supported.
Developing the Library
It turns out that parsing partially returned responses is actually pretty tricky. I started by writing a simple parser just to handle a couple cases, and quickly realized that would be really annoying to manage and maintain. That led me to checkout using finite state machines to handle some of the logic, but it still wasn’t generalizable enough yet, and I thought there must be a better way. The answer was literally looking me in the face the whole time — tree sitter

Tree sitter is literally designed to handle these incremental parsing cases to handle things like syntax highlighting in your IDE. It’s lightning fast compared to my python code because it is written in C by much smarter people than me. It even has bindings for Python, so integrating it into my project is straightforward.
Now even though I’m running the parsing logic on every loop, after profiling the data I can see that tree sitter is only taking about half a millisecond to parse in a simple case.
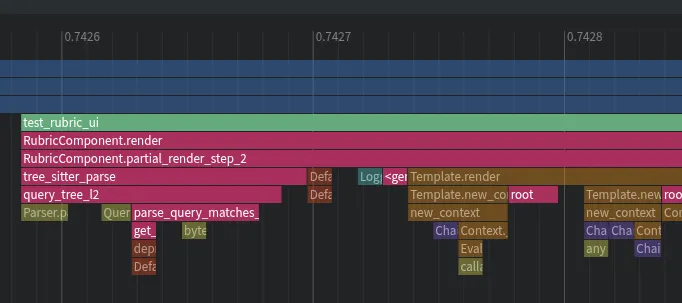
Tree sitter has another awesome feature that I’m taking advantage of — queries. It has a built in query language that supports pattern matching which makes it easy to pull out specific keys and values. Since we’ll always know the structures ahead of time we can dynamically construct queries to pull out what we need without any complex parsing logic.
The last benefit of using tree sitter is that there are already grammars for popular formats like JSON. Instead of needing to write my own grammar from scratch I can use the tree-sitter-json grammar as a python package. I think there could be some cool stuff I could do by defining a custom grammar instead of relying on JSON, but using JSON allows for easy integration and familiarity for other users.
Test it out in your projects
If you want to use the library yourself you can check install it from pypi.
I’m still working on building out more features, and making the library more robust. Some things I have on my roadmap are — supporting dataclasses, supporting more complex nesting of objects, and re-examining the queries to make them simpler.
If you’re interested in using or helping out with this project, it’s MIT licensed, and you can find the github repo here.