Serverless ML Stock Predictions
Sep 6, 2021
"Stocks In English" is an app that scrapes financial articles then uses machine learning to determine their sentiment.
The sentiment trends are shown in the app and the whole dataset can be downloaded to be used with other machine learning models.
I created this app because there weren’t many good datasets of real financial articles, and I wanted to learn more about serverless infrastructure. The main components of the app are the serverless infrastructure and machine learning.
I've since shut down the app...
Serverless Infrastructure
Serverless infrastructure can be leveraged to run machine learning functions that are not often used. By hosting my machine learning model serverlessly, I only pay for the compute time that I need instead of paying monthly for a virtual server.
In the case of this app, I only pull articles every three days, so I save around $10–$20 per month by hosting it serverlessly.
To create this app I used several serverless resources listed below. To orchestrate them I used AWS Serverless Application Model (SAM).
SAM allows you to define infrastructure as config using YAML, helping manage resources in one place.
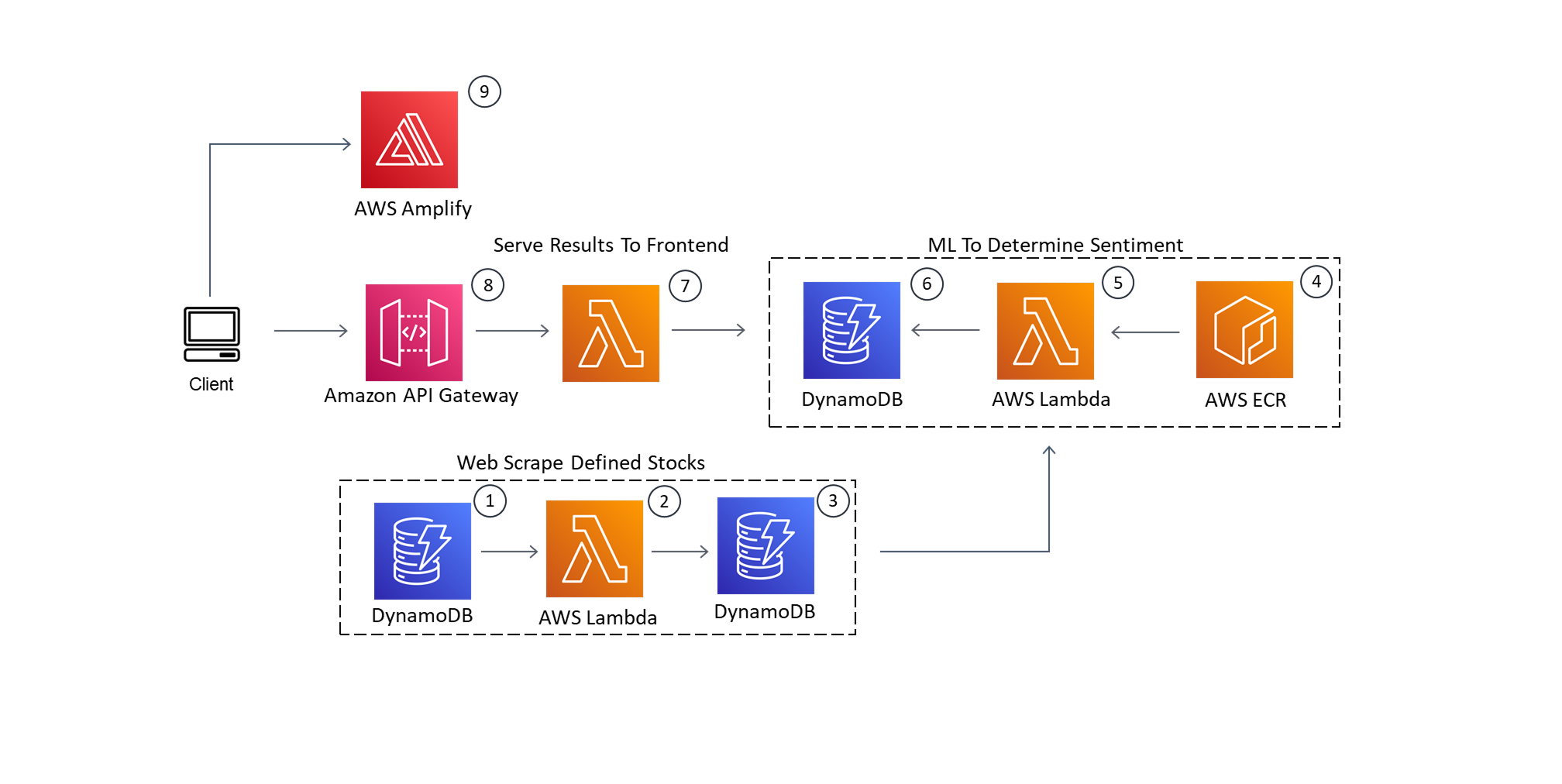
I used five AWS resources: Amplify, DynamoDB, Lambda, Elastic Container Repository (ECR), and API Gateway.
Architecture diagram:
Components
-
Database table that holds all the stock ticker symbols to be scraped
(future-proofing for user requests) -
Function that crawls and scrapes data based on requested stock tickers
(runs every 3 days) -
Database table that holds the scraped data results
-
Container repository that holds the image for the ML inference function
-
Lambda function that determines sentiment of scraped text
(triggered when new data is added to DynamoDB #3) -
Database table that holds the analyzed data
-
Function to pull data for the API
(does preprocessing before serving to frontend) -
API Gateway to serve data to the frontend
-
Website hosting with Amplify
View the SAM YAML file on GitHub
Machine Learning
I ran into a couple of challenges due to serverless limitations, mainly package and model size.
To be fair, I could have used AWS SageMaker, which would have solved some issues, but it adds costs and complexity. In future projects I plan to explore it.
Key challenges:
- Lambda package size limit: 250MB.
- My small BERT model was ~115MB, traditional BERT ~400MB, and TensorFlow library ~2GB.
-
Solution: AWS now supports custom Docker runtimes for Lambda (up to 10GB).
-
Library size: Hugging Face Transformers was ~9.2GB!
- Uploading to AWS took ~1 hour.
- Solution: switched to TensorFlow and fine-tuned a smaller pre-trained BERT model instead.
For training, I used the Financial News Sentiment dataset from Kaggle.
I trained only on positive and negative statements, leaving out mixed for now.
Financial News Dataset on Kaggle
Web Scraping
Web scraping was an important part of this project. I didn’t have much experience with it, so it was a challenge.
Approach:
- Start with search results for financial articles from Google Finance.
- Pull the URLs of all listed articles.
- Scrape the HTML content of each page.
- Extract the first couple of sentences.
- Save results into a DynamoDB table.
Future Steps
This project sparked my curiosity about other AWS services I want to try in the future:
- AWS SageMaker — for better ML pipelines and version control
- AWS Step Functions — for organizing Lambda workflows as complexity grows
- AWS Cloud Development Kit (CDK) — define infra in Python instead of YAML